
Bonjour,
Je suis tomber sur cet article:
http://thebacklog.net/2011/04/04/a-nice-picture-of-dependency-hell/
Voila la visualisation des dépendances des logiciels et libs:
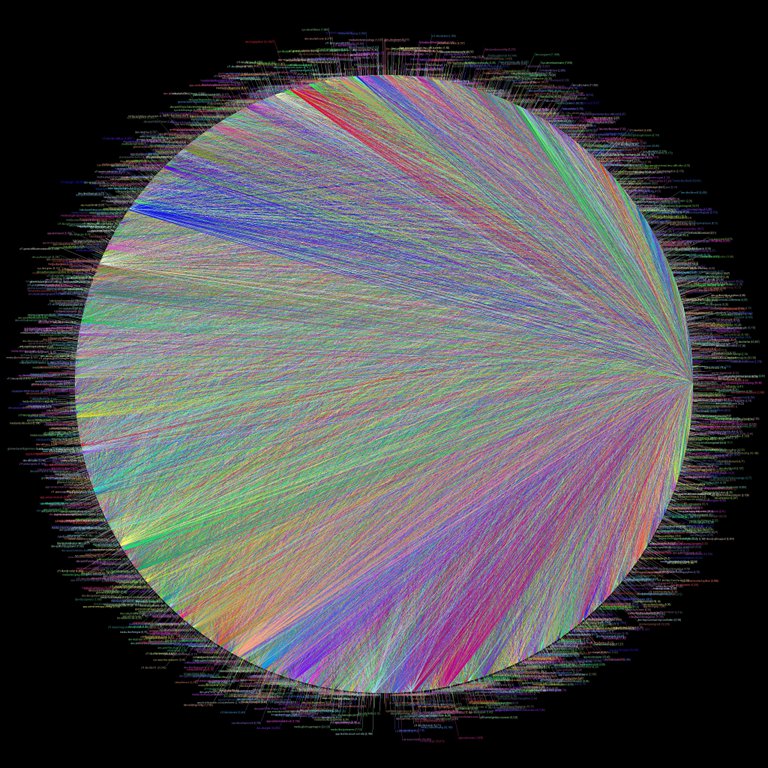
Il y as des dépendances dans tout les sens, mais le pire c’est les dépendances circulaires, il vous faut A pour avoir B, mais B pour avoir A… et donc comment vous faite depuis 0? Vous mettez un A compilé trouvé sur internet, vous compilez B, puis compilez A et écrasez le A de internet.
En 5 ans le nombres de packets à augmenté, les dépendances se sont complexifié. Cela rends la maintenance d’un OS plus compliqué. Faire l’arbre de dépendances pour calculer les dépendances à installer avant le packet deviens de plus en plus complexe.
Un logiciel peu vouloir une lib en version 1.2 et pas moins ni plus, et un autre utilise cette libs en version 1.3 minimum.
Vous développeur, que pouvez vous faire?
A votre niveau, que pouvez vous faire? Voila une serie de conseille qui sont à appliquer avec intelligence, et non comme des régles strictes:
- Minimiser le nombre de dépendances: Cela permet de rendre la compilation plus facile pour les contributeurs potentiels. D’avoir moins besoin d’adapter votre logiciel pour les changements d’API des libs que vous utilisez. Augmente les performances de votre logiciel (1 relocation en moins, peu être critique quand vous l’appelez comme un fou dans une boucle) et permet à votre compilateur le LTO et/ou d’inline la fonction qui vas bien et d’utiliser moins de mémoire. Permet de minimiser la taille en supprimant tout les codes compilé peu/pas utilisé. Cela permet de minimiser les failles en minimisant le code chargé et donc le nombre de faille potentiel. Comment? En analysant les choses que vous n’utilisez pas: Certain lie des libs sans même utiliser la moindre functions. Si vous utilisez très peu de function d’une libs, il est souvent plus intéressants de refaire ces functions dans votre programme (sauf si vous ne voulais pas avoir à charge leur maintenance: par exemple les functions de hash de openssl qui sont actualisé pour exploiter au mieux les instructions du cpu)
- Etre tolérant sur les versions de libs supporté: Cela permet de ne pas rentré en conflit avec d’autre logiciel demandant une version supérieur ou inférieur d’une lib. Comment? En ne pas se jetant sur la dernière fonctionnalité de vos libs (mais utiliser la si c’est un avantage majeur: J’utilise dans Ultracopier Qt 4.4 pour la détection de l’espace libre, impossible de faire autrement sans rajouter une dépendance problématique)
- Pour le packaging sous Windows, vous pouvez utiliser une copie privée de vos dll, et donc avoir des versions spécifique sans que cela rentre en conflit avec les autres logiciels. Cela n’est pas applicable au OS qui mettent en commun les lib et qui ont une gestion de packets.
Si vous faite une lib
Si vous faite une lib, voila les conseilles:
- Dépendance: évitez de mettre en dépendance une libs qui directement ou non dépende de votre libs.
- Versioning et API: Exploser une API stable, que vous aller changer un minimum de fois en cumulant les changements. Mettez un numéro de version, avec un nombre majeur caractérisant un changement d’API, et un nombre mineur pour les changements interne qui ne change pas l’API.
Voila, en espérant vous avoir éclairé.
