CatchChallenger 2 introduit l’infrastructure de cluster. Ce qui implique des changements coté datapack (base commune pour faire tourner les avatars entre les serveurs, et partie spécifique), les changements sont principalement fait. Des changements coté base de données, qui en plus d’avoir les obligations du datapack se doit d’être performante et de marcher sans les auto increment pour les index (pour les bases ne le supportant pas), il y aura encore des changements.
Pour les serveurs, je tiens à garder le serveur Qt (avec une interface et de beaux boutons) pour faciliter la mise en place de petit serveur perso, et le serveur epoll linux simple en CLI pour des serveurs moyens. Le faite de n’avoir qu’un exécutable, une base de donnée et un port à ouvrir rends simple l’utilisation du serveur mais cela permet aussi de ce passer d’une surcouche de communication inter-serveur qui peu être coûteuse en performance.
Le mode cluster ce compose de 2 types de base de données distante (login et common) qui vont être accédé par plusieurs serveurs. Et une base de données spécifique par serveur (qui peu être distante ou non). Il y a des serveurs de login pour gérer l’authentification, le changements de la liste des avatars, création d’avatars et de l’envoie de la base du datapack. Il peuvent servir de proxy pour que le joueur ne doivent pas se reconnecté sur le game serveur (meilleur anonymisation car les ip des games serveurs ne sont pas connu, mais à cause des connexions maintenu ouverte cela à un coût). Un serveur master qui est responsable d’unifier les configs qui ne doivent pas varier en fonction du serveur, d’avoir une base datapack unifié et d’avoir un point de centralisation pour poser les verrous sur les avatars. Il n’est connu que des serveurs login et game. Les games serveurs sont la où joue les joueurs. Si les joueurs sont directement connecté sur les games serveur, les logins serveurs peuvent être coulé par une attaque DDOS sans que les joueurs déjà connecté soit affecté.
La communication inter-serveur n’est pas facile sachant qu’il faille tenir compte des RTT car les serveurs au quatre coin du monde vont avoir des latences de communications. La bande passante peu être limité dans un pays en voie de développement ce qui rends la compression obligatoire. La cryptographie l’est pour certifier que les serveurs autorisé peuvent bien ce connecter entre eux et que les données ne puisse être intercepté (idem pour les bases de données). La modification dynamique de l’infrastructure doit être pris en charge pour ajouter ou retirer à la demande des logins ou games serveurs sans rien redémarrer. Les serveurs doivent se comporter comme un cluster. Il faut prendre en compte aussi les possibles déconnexion temporaire avec le master serveur. C’est la ou l’asynchronisme surtout coté base de données prends tout sont sens.
Pour idéalement une bonne portabilité sur tout les environnements mais aussi de bonne performance (le QDataStream + QByteArray de Qt à beau être sécurisé et très commode, il est extrêmement peu performant), le passage d’un maximum de code en C++11 et surtout les sérialiseurs (avec des buffers pré-allouer pour éviter des pressions sur la mémoire à cause de new/malloc trop fréquent) est en cour. Mais je ne pense pas pouvoir tout bouclé pour la version 2 donc la dépendance avec Qt sera toujours de mise. Le passage en C++11 me permet un certain nombre de chose via la norme même, et me force à faire du code souple Qt <-> C++. Cela permet aussi d’exploiter les parties spécifiques à l’OS qui est totalement abstraite en Qt et donc qui n’est pas accessible. Je pense aussi à libOS qui veux être dans la branche principale de linux, j’ai un peu peur de cela car certain dev newbies ont tendance à vouloir le contrôle sur tout, soit car il ont entendu que ça augmenterai les performances (ce qui est vrai seulement si ont sais s’en servir) ou simplement pour se sentir aux commandes (en oubliant la sécurité, et l’isolation des taches). Sans parler que refaire un ordonnanceur, un driver, … et le maintenir est une grosses charge supplémentaire qui fait exploser le développement à faire. Idéalement si le master serveur et les logins serveur font 10Mo et utilise 1Mo de mémoire ou max <10Mo ça me vas.
Un support de NoSQL ne me semble pas réaliste ainsi que les requêtes préparé pour cette version. Par contre vu que MySQL 5.5+ ce généralise je verrai si j’ai le temps de faire le support de MySQL en asynchrone.
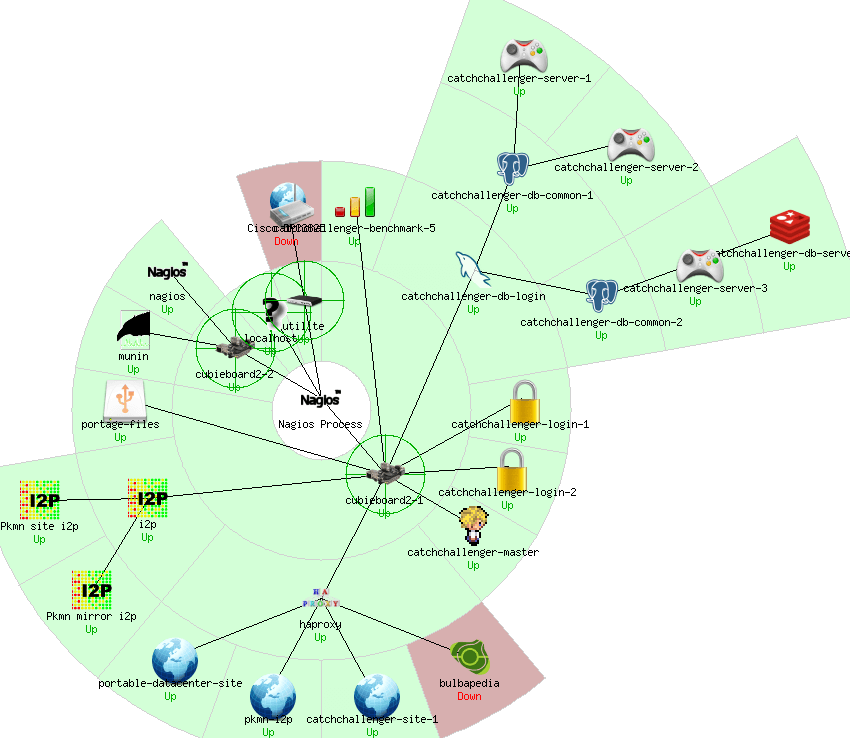
Le portable datacenter continue à grandir, ayant changé ma connexion pour 2M en download et upload, cela me permet de faire un peu d’hébergement (site + 200 joueurs). Peu de services sont visibles mais pas mal de service en background sont la. Il continue à être un mix de machine légère (rpi 1, cubieboard2, ordoid u3, cubox-i, fit pc 1…, donc Geode LX800, Cortex A9, ARM1176JZF-S, Cortex A7, de 1 à 4 coeur par config). Le tout monitoré sous nagios + munin. Avec un peu de btrfs, beaucoup d’ext4. Lxc + grsec comme système de virtualisation, et gentoo en -march=native pour les hôtes et -march=native pour les hardwares où j’ai de multiple exemplaire et -march=generic pour les autres. Cela me fait un bon parque pour faire de l’auto benchmarking.