
Salut,
Dans le cadre de mon passage en tier 3 du data center de Confiared, j’installe le système solaire.




Bye
News sur le matos informatique
Salut,
Dans le cadre de mon passage en tier 3 du data center de Confiared, j’installe le système solaire.
Bye

J’ai fait le choix d’utiliser des petites nodes avec des Cortex A53. Justement pour pouvoir avoir du hardware dédié pour le haut de gamme. Avantage du VPS avec beaucoup de bénéfices du dédié dans notre datacenter (Confiared).
Par chance, ces CPU son non affecté par Meltdown, Spectre. Les CPUs sont comme le code, moins ils sont complexes, moins il y as de bugs. Je pense que les constructeurs vont envisager de plus en plus OpenRISC, Google appuie le RISC-V.
Source: https://www.xda-developers.com/risc-v-cores-and-why-they-matter/
Bonjour,
Je vais parler de l’efficacité énergétique dans les systèmes de stockages. Ici je vais faire de grosses approximations. Merci pour votre compréhension.
L’aspect le plus évident c’est que si il y as moins de consommation énergétique, les machines tire moins sur les factures d’électricité. Cela permet d’avoir moins d’émission de chaleur, ce qui allonge la durée de vie de ces derniers.
Les pics de consommations crée des problèmes divers tel que la difficulté sur les systèmes embarqué de lancé le hdd par manque de puissance, … cela oblige de concevoir le buffer avec la consommation max qui peu être trés différente de la consommation réel.
Le système d’exploitation considere une données écrite quand elle à été envoyé au hdd. Car même en cas de coupure, le hdd doit avoir assez d’énergie accumulé pour écrire ce qu’il as dans le buffer. Plus le disque est performant, plus le buffer pourra être grand. Plus le buffer sera grand, plus le disque pourra minimiser les changements de place de la tête de lecture pour optimiser ces déplacements.
Ce qui est intéressant dans les SSD et la nouvelle génération 3D XPoint c’est que l’énergie consommé est contante et bien plus basse. Ce qui permet de faire des buffers bien plus gros, ce qui dans ces proportion permet aussi de de plus écrire simplement plein de petit bloque mais de les groupes en super bloques (optimisation des technologie flash et augmentation de leur duré de vie).
Il faut encore adapter un certain nombre de couche logiciel pour prendre en compte certaine particularité comme le multi-queue. Mais l’impact énergie<->performance est relativement transparent.
Bonjour,
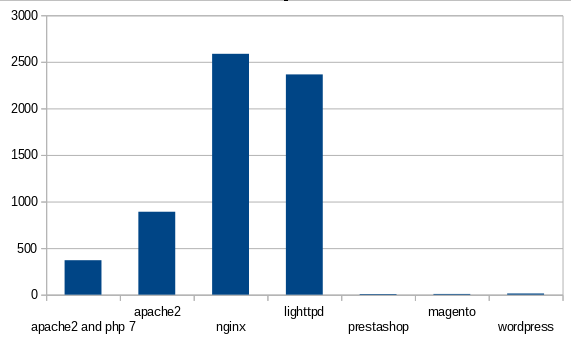
Benchmark fait dans un vm LXC, sur un Odroid C2
Pour sa conception, CatchChallenger est 10x-100x plus rapide…
Bye
Bonjour,
Pour les besoins de CatchChallenger, j’ai exploré des base de données NoSQL.
C’été mon 1er choix. La mise à l’échelle (scalabilité) est bonne. Il prends en compte le datacenter.
Mais le pannel de controle fort sympatique qu’est OpsCenter est réservé a RedHat et debian, pourquoi il ne peu pas juste demander les dépendances qu’il as besoin, voir les embarqués si elle ne sont pas trés commune?
J’ai été obligé de rajouter des clef primaire la ou ce n’est pas utile. Les index uniques sur du multi colonne ne sont pas natif et vu que j’ai rien compris sur comment faire ce CUSTOM INDEX et que cela affecte les performances, j’ai dit adieux.
Sur gentoo, je suis bloqué en 2.6 à cause d’un conflit de dépendances avec kleopatra (KDE). Même si c’est plus de la faute de kleopatra, c’est génant.
J’ai donc tenter sur un de mes ARM, et là on me dit que sur ARM, et particulièrement ARM 32Bits cela ne sera jamais supporté. Donc poubelle.
Bien, compatible car j’utilise des functions simples (ce qui me rends compatible avec 100% des SQL), je note cependant que certaines fonctionnalités ne sont pas dispo sur toute les architectures: TokuDB pas dispo sur ARM…
Nous somme en 2016 les gas! Mềme Mingw supporte gcc 4.9, ce qui donne accès a une abstraction à la fois de l’architecture et de la plateforme.
Pour être indépendant de la plateforme il y as plein de libs connu, sans compter la compatibilité entre les unix, et grace à mingw avec windows.
Coté architecture, il faut toujours avoir un failback en C/C++ pour les architectures moins optimisé mais pour avoir un support et du code lisible et vérifiable. Le double support 32Bits et 64Bits est super facile à faire si ont respecte la norme. Hors mit ca je vois pas la moindre raison que votre code C/C++ ne marcherai pas sur une autre architecture.
Le 32Bits ne vas jamais disparaître car c’est le moyen le plus effectif pour avoir des système embarqué avec peu de consommation. En plus cela permet de réduire lors d’utilisation forte de pointeur l’empreinte mémoire (jusqu’as 2x de réduction, BTree, hash table, …). Si vous utilisez moins de 4Go de mémoire, le 32Bits est fait pour vous. C’est pour cela qu’existe aussi x32, cela permet sur x86_64 de tiré partie du mode 64Bits mais en ayant un mode d’adressage en 32Bits (donc max 4Go) mais avec la réduction de l’empreinte mémoire du 32Bits. Cela ne me surprendrai pas de savoir que les GPU ont des cpu en 32Bits.
Bye.
Salut,
La question du jour: il vaut mieux un hardware Multicœur ou pas?
Pour optimiser le multi-threading et plus précisément les mutex/valeur atomique il vaut mieux un gestion hardware bonne. Cela permet d’avoir de bonne performances lorsque un entier ou un bout de code ne doit être accédé que dans un thread à la fois. Cela veut dire garder des valeurs dans la mémoire commune, cela peu être le L3, la mémoire principale, bref quelque chose de plus lent que le L1 du cpu.
Cela n’as pas d’influence si cette partie du code est peu utilisé face au reste du code (peu de synchronisation des threads et peu de passage de donnée d’un thread à l’autre).
Si vous avez que un cpu (forcer cela dans votre noyau linux), un certain nombre d’optimisation peuvent être faite (garder les lock en L1 par exemple), peu de changement de contexte avec l’utilisation des threads, …
Bien souvent, essayer d’exploiter le multi-cpu demande plus d’effort ou le code résultant est plus lent. En mono cpu vous êtes plus optimisé, et en mono-thread plus optimisé mais vous n’exploitez pas tout les coeurs (pour un serveur cela n’est pas grave vu que les autres application tournant sur votre serveur se répartisse les coeurs restant).
Donc je vais préférer un bon monocoeur performant avec le noyau qui vas avec, ou un quad coeur, mais pas un dual coeur, même si la mode est a cela.
Bye
Bonjour,
Pour moi les CPU haute densité type Cavium ThunderX CN8890 ARMv8 sont l’avenir dans le monde des serveurs, AMD a beau sortir ces Opteron A1100, ont est loin des 4$ par cpu de pine64 ou 8$ par cpu des raspberry pi.
Point que je prends en compte:
A standard Linux system that struggles at forwarding 500,000 packets-per-second
, si les meilleurs x86 ont du mal, les ARM qui ont moins de instruction par secondes aux MHz…
Donc pour moi la carte H270-T70 de gigabyte est une bonne direction.
Bye,

Salut,
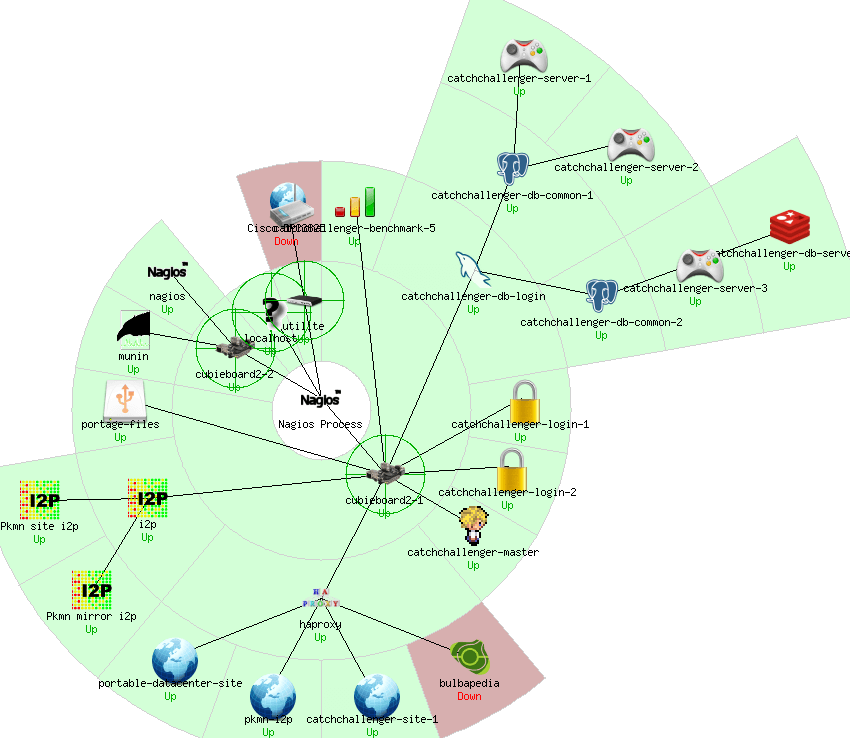
Je souhaite revenir sur quelque mois d’utilisation intensive de mon cluster ARM. L’image n’est pas celle actuel mais donne une idee de mon portable datacenter.
Je trouve dommage que pour avoir java 8, il faille utiliser le java de oracle et que ce dernier n’est pas actualisé et donc potentiellement avec des failles. Java est une technologie qui permet de faire fonctionner une application que vous soyez sur ARMv6, v7, x86. Mais cela ajoute une abstraction assez casse pieds qui bloque l’accès a certain truc spécifique de l’OS et ne permet de de descendre aussi bas dans le optimisation que en c/c++.
Nagios est performant, munin est pourri cote performance et plombe ces propres mesures (Surtout a cause du spawn de processus). Le backup sur une node en btrfs, le but étant d’avoir des backups différentiel.
Il faut faire très attention à la bande passante inter processus/thread qui est très réduite, sans même parler des communication externe. Donc il vaut mieux privilégier plusieurs processus mono thread qui travaille en local sur leur données locales que du multi-thread qui passe plus de temps à faire tourner les données entre plusieurs threads et se coordonner le travail que à travailler. L’ordonnanceur cpu vas naturellement repartir chaque processus par cpu (base de donnée, noyau, serveur authentification serveur de jeu). Le multi-thread peu être simpa si vous avec qu’un service sur un matos multi coeur (votre base donnée sur un quadcore, bien que dans ce cas l’ordonnanceur disk, le FS et le disque en lui même auront plus d’influence). Mon programme est plus simple est bien plus rapide sur ARM vu que je n’utilise pas de verrou, et je fait juste tourner plusieurs serveur en parallèle. Le joueur n’as plus qu’as jouer sur le même serveur que ces amis, ce qui déporte le problème du multi-thread sur l’humain. Cela permet que le serveur consomme 10-50x moins de cpu que le noyau linux pour gérer les packet tcp.
Grsec combiné à certain manque d’optimisation sur ARM (hardware comme software) fonds que certaines fonction sont bien plus lente (memcpy() vs accès non aligné, presque aucune différence de performance sur x86, ARM + grsec 7x plus performant sur les accès non aligné). Une taille fix en mémoire de l’application aide à ne pas faire de pression sur le code de gestion de la mémoire.
La consommation et prix de la puce est défini par le nombre de transistor dans la puce. Si vous avec une puce trop généraliste vous perdez sur cela, par exemple j’ai pas besoin du GPU ni du FPU pour mes serveur. Par contre j’ai besoin de l’ALU et des unités SIMD. J’aurai aussi besoin d’ASIC AES et SHA224, un générateur de nombre aléatoire pour optimiser la partie cryptographique des applications (connexion des utilisateurs, des serveurs aux bases de données, des serveurs entre eux). La communication chiffré est de nos jours obligatoire, donc le volume transmit via une connexion chiffré même établis en permanence a un impacte sur les performances, les accélérateur hardware se rapporte à un système de chiffré qui hélas se font brisé de plus en plus rapidement). Je n’est presque jamais vu d’accélération sur la compression, si cela est possible. Pas mal de puce ont démontré un meilleur ratio GFLOPS/W car leur circuit sont fix et optimisé. (GPU passage de statique, partiellement programmable, totalement programmable)
Finalement les performances son bien meilleur que un gros serveur x86 (15x la vitesse de la DDR3), plus de sécurité car il y as beaucoup moins de vm par hardware car il y as plus de hardware pour le même prix/consommation énergétique. Je suis très content de mon cluster MMORPG sur ce cluster qui peu tenir d’apres mes testes en gardant beaucoup de marge 30 hardware*4 cpu*100k utilisateur=12 millions de joueur pour moins de 100W.
CatchChallenger 2 introduit l’infrastructure de cluster. Ce qui implique des changements coté datapack (base commune pour faire tourner les avatars entre les serveurs, et partie spécifique), les changements sont principalement fait. Des changements coté base de données, qui en plus d’avoir les obligations du datapack se doit d’être performante et de marcher sans les auto increment pour les index (pour les bases ne le supportant pas), il y aura encore des changements.
Hello,
Cut one wire of power source, connect your 2 wire of you ampermetter to the 2 part of one wire, take care to be in 10A mode to don’t burn the fuse.
Here you have the power consumption on 5V line (then without the adaptador power, I have used an DT-830B):
ODROID-GameStation-Turbo-0.10_20140525-X
4 thread: 1.42A, 7.1W
1 thread: 0.75A, 3.75W
0 thread: 0.58A, 2.9W
99°C max temp
USB not work, then my usb joystick not work, 100% at all time.
It’s just crazy in fonction of ubuntu server:
4 thread: 1.20A->1.46A, grow slowly and after is random: 6-7.3W
1 thread: 0.48A, 2.4W
0 thread: 0.29A, 1.45W
85°C max temp
Only use micro SD card, network (1000Mbps), no thing more. No HDMI, no sound, …
Cheers,

